Para quem precisa usar dois critérios dentro da formula CONT.SE , segue uma solução sem a utlização de Matricial:
=SOMARPRODUTO((A1:A10=Criterio1)*(B1:B10=Criterio2))
Diário de Informática -Diariamente me deparo com problemas técnicos, e resolvi compartilhar há quem interessar e também uso esse blog como um diário, a final se não anotamos as soluções, esquecemos... Dicas em geral sobre: office, windows, linux, sql server, oracle, internet, impressoras e Outros.
terça-feira, 29 de novembro de 2011
Criando e gerenciando usuários no GNU/Linux
Introdução
Uma das coisas que torna seguro o sistema operacional GNU/Linux (na verdade, qualquer sistema baseado no Unix), é a sua exigência de que cada coisa tenha dono e permissões de uso. Assim, para que seja possível restringir ou permitir o acesso e o uso de determinados recursos a uma ou mais pessoas, é necessário que cada uma tenha um usuário devidamente criado no sistema operacional. Mas, como criar usuários no Linux? Como alterar as características desses usuários? Como bloquear ou mesmo eliminar um usuário do sistema? É isso que você verá nas próximas linhas.Por que criar usuários no GNU/Linux?
Criar uma conta para cada usuário no sistema operacional não serve apenas para restringir ou permitir o acesso aos recursos oferecidos, mas também para respeitar o espaço que cada pessoa tem. Com uma conta, uma pessoa poderá ter os seus próprios diretórios, personalizar o seu desktop, ter atalhos e configurações para os seus programas preferidos, entre outros. Além disso, mesmo que o computador onde o GNU/Linux está instalado seja usado apenas por uma pessoa, é recomendável criar um usuário próprio para ela. Mas, por qual motivo, se o sistema já conta com um usuário nativo, o root? O usuário root é o que "manda" no sistema, pois ele tem poderes de administrador, o que significa que ele tem acesso a todos os recursos do sistema operacional. Usá-lo no dia-a-dia não é recomendável, pois se o computador for tomado por outra pessoa ou se o próprio usuário fizer alguma coisa errada, o sistema operacional poderá ser seriamente comprometido.Respondendo a pergunta desse tópico com base nisso, a resposta é muito simples: deve-se criar usuários no GNU/Linux meramente para permitir a sua utilização por cada pessoa.
Entendendo o controle de usuários no GNU/Linux
Para criar, gerenciar ou eliminar contas de usuários no GNU/Linux, é necessário estar "logado" no sistema operacional com o usuário root (ou outro usuário que tenha privilégios de administrador). Os motivos para isso são óbvios: somente usuários autorizados é que podem manipular outras contas, do contrário, a segurança do sistema seria seriamente comprometida, pois qualquer usuário poderia criar, alterar ou apagar contas. Note que, dependendo das configurações do seu sistema, pode ser necessário executar cada instrução antecedida do comando 'sudo', como acontece por padrão com a distribuição Ubuntu.Antes de criar e controlar contas no GNU/Linux, é conveniente entender como o sistema operacional lida com isso. Em geral, cada conta criada fica armazenada em um arquivo de nome passwd localizado dentro do diretório /etc/ (ou seja, seu caminho completo é /etc/passwd). Esse arquivo contém várias informações sobre cada usuário:
- o seu nome de login (ou seja, o nome que é necessário digitar para entrar no sistema);
- senha (neste caso, a informação da senha pode estar criptografada ou em outro arquivo);
- UID (User IDentification), ou seja, número de identificação do usuário;
- GID (Group IDentification), isto é, número de identificação do grupo do usuário;
- informações adicionais sobre o usuário (nome completo, dados de contato, etc);
- diretório "home", ou seja, o diretório principal de cada usuário;
- shell do usuário, uma espécie de programa que interpretará os comandos que o usuário digitar.
Para que você possa entender melhor cada um desses itens, vamos analisá-los usando como base a linha abaixo extraída de um arquivo /etc/passwd, que mostra a posição que cada uma das informações acima ocupa:
tintin:x:1001:500:TinTin,Belgica,846-846:/home/tintin:/bin/bash
Note que cada parâmetro do usuário é separado por : (dois pontos). Vamos estudar cada um:
tintin: é neste ponto que fica localizado o nome de login do usuário, neste caso, tintin. Esse nome não pode ser igual a outro já existente no sistema e, geralmente é limitado a 32 caracteres. Todavia, dependendo da configuração aplicada, o nome pode ser "case sensitive", ou seja, diferencia letras maiúsculas de minúsculas. Assim, 'wester' será diferente de 'wEster', por exemplo;
x: essa posição indica a senha do usuário. A letra x informa que a senha está armazenada e protegida dentro do arquivo /etc/shadow. Se houver um asterisco (*) no lugar, significa que a conta está desativada. Todavia, se não houver nada, significa que não há senha para esse usuário. Em alguns casos, embora isso não seja recomendável, a senha pode estar inserida diretamente ali, mas criptografada;
1001: esse campo indica o número UID (User IDentification) do usuário, mas você pode estar se perguntando o que é isso. Como o próprio nome informa, é número que serve para identificar o usuário. Em geral, o sistema pode suportar UIDs que vão de 0 a 4.294.967.296, embora alguns sistemas limitem esse número a valores inferiores. Normalmente, o UID 0 é atribuído pelo próprio GNU/Linux ao usuário root. O sistema também pode criar automaticamente usuários para a execução de determinadas rotinas e atribuir a eles UIDs baixos, como 1, 2, 3 e assim por diante. Note que, em nosso exemplo, o UID do usuário é 1001. Para usuários "humanos" do sistema, realmente é uma boa prática criar UIDs mais altas, para fins de organização;
500: esse é o campo que indica o GID (Group IDentification) do usuário, isto é, o número de identificação do grupo do qual ele faz parte. Assim como no UID, geralmente o usuário 0 é indicado para o grupo do usuário root. Note, no entanto, que um mesmo usuário pode fazer parte de mais de um grupo (geralmente, o GNU/Linux permite a participação do usuário em até 32 grupos). Mas qual a vantagem de se ter mais de um grupo? Simples: suponha, por exemplo, que você queira que somente os funcionários do departamento contábil de sua empresa acessem os arquivos disponíveis na pasta /contabilidade/. Para isso, você cria um grupo e uma definição que faz com que apenas os usuários desse grupo tenham direito ao acesso. Feito isso, basta adicionar ao grupo cada usuário do departamento contábil. Assim, somente eles acessarão o diretório. Via de regra, o sistema operacional cria um grupo para cada conta de usuário criada;
TinTin,Belgica,846-846: esse campo é muito interessante, pois permite a inclusão de informações adicionais sobre o usuário. Também chamado de GECOS (General Electric Comprehensive Operating System) em alusão a uma funcionalidade existente em um sistema operacional Unix que tinha esse nome, esse campo serve para, por exemplo, cadastrar o nome completo do usuário, seu endereço, seu telefone ou o seu ramal, etc. Cada informação é separada da outra por uma vírgula, por exemplo: Emerson Alecrim,Rua X,1234-4321. Na prática, você pode inserir as informações que achar melhor, não apenas os dados informados anteriormente;
/home/tintin: cada usuário criado no sistema tem direito a uma pasta "home", ou seja, uma pasta sua, para uso exclusivo. É neste campo que você indica onde estará essa pasta. Em geral, essas pastas ficam dentro do diretório /home/, mas você pode definir o diretório que quiser (ou mesmo não indicar nenhum);
/bin/bash: esse é o campo que informa qual o shell (interpretador de comandos) de login que o usuário utilizará. O GNU/Linux trabalha com vários, entre eles, o bash, o sh e o csh. Caso nenhum shell seja informado, o sistema utilizará o bash como padrão.
Criando usuários no GNU/Linux
Agora que você já conta com informações importantes sobre o gerenciamento de usuários no GNU/Linux, chegou a hora de criar contas. Para isso, você pode abrir um terminal e utilizar o comando adduser (dependendo do seu sistema, o comando pode ser somente/também useradd), que é aplicado da seguinte forma:adduser opções usuário
Em opções, você pode colocar parâmetros específicos para a configuração da conta de usuário que será criada. Você pode usar vários parâmetros (veja uma lista completa digitando man adduser no terminal), entre eles:
adduser -disabled-login usuário: faz com que a conta do usuário seja criada sem a solicitação de uma senha (ou seja, não executa o comando passwd). No entanto, a conta não poderá ser usada até que o usuário defina sua senha de acesso;
adduser -force-badname usuário: em geral, os sistemas GNU/Linux checam se a conta criada pode ter em seu nome (ou mesmo na senha) algo que aumente os riscos ao sistema. Com esse comando, o sistema é instruído a não fazer esse tipo de verificação;
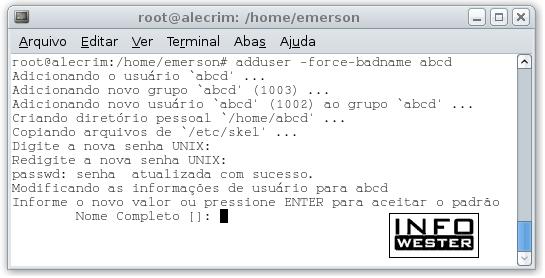
adduser -group grupo: com esse parâmetro, ao invés de uma conta de usuário, um grupo é criado. Para essa tarefa também pode-se utilizar o comando addgroup;
adduser -home diretório usuário: com essa opção, você define em qual diretório ficará o "home" do usuário. Se esse parâmetro não for usado, o sistema criará o "home" no diretório padrão (geralmente, em /home/nome_do_usuário). Se preferir que nenhum diretório desse tipo seja criado, você pode utilizar a opção -no-create-home (não recomendável);
adduser -uid número usuário: quando usuários são criados, o sistema geralmente adiciona a eles UIDs sequenciais, mas você pode especificar o UID que quiser usando o parâmetro uid seguido de um número, por exemplo, uid 31415. Note que, em muitas distribuições GNU/Linux, você pode utilizar apenas a letra u ao invés de uid. Note também que o GID do usuário será igual ao valor informado por você, a não ser que você especifique outro através da opção -gid, vista abaixo;
adduser -gid número usuário: semelhante ao parâmetro acima, mas especifica manualmente um grupo para o usuário ao invés de criar um parâmetro. Note que, em muitas distribuições GNU/Linux, você pode utilizar apenas a letra g ao invés de gid. O gid informado deve ser o de um grupo já existente;
adduser -ingroup grupo usuário: adiciona o usuário criado a um grupo já existente, ao invés de criar um novo grupo para ele;
adduser -shell shell usuário: através desse parâmetro, você pode especificar qual será o shell padrão do usuário. Em alguns sistemas é possível usar a letra s ao invés da palavra shell.
Para servir de exemplo, vamos criar um usuário de nome wester. Esse usuário deverá:
- ter um UID de número 27182;
- ser inserido no grupo infowester (já existente).
Veja como ficará o comando:
adduser -uid 27182 -ingroup infowester wester
Assim que esse comando for digitado, o sistema pedirá que você digite duas vezes uma senha para o usuário. Em seguida, perguntará as informações adicionais, como nome completo, telefone, etc. Note que você pode deixar essas informações em branco, se preferir. Você deve ter notado pelo comando acima de que é possível utilizar mais de uma opção ao mesmo tempo no comando adduser.
Eliminando usuários no GNU/Linux
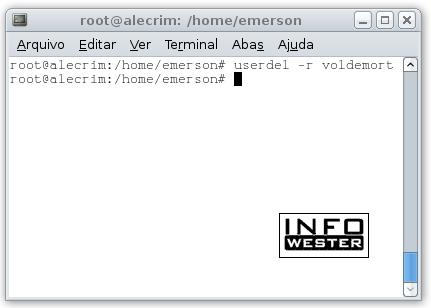
Se você precisa apagar um usuário, saiba que o procedimento é fácil. Basta digitar o comando userdel seguido do nome do usuário. Por exemplo:userdel voldmort
Se além de eliminar esse usuário do sistema você quiser que sua pasta "home" seja apagada (junto com todo o seu conteúdo), basta digitar o comando userdel seguido do parâmetro -r e do nome do usuário:
userdel -r voldemort
Ao fazer isso, certifique-se que o usuário tem cópia de todos os arquivos a serem apagados, quando cabível.
Alterando e controlando a senha do usuário
Por segurança, é recomendável alterar a senha de todos os usuários periodicamente. Para isso, usa-se o comando passwd. Se qualquer usuário quiser alterar a sua própria senha, basta digitar apenas passwd em um terminal. Quando isso ocorrer, o sistema pedirá que o usuário digite a sua senha atual e, em seguida, pedirá a nova seqüência, que deve ser informada duas vezes, para confirmação.O usuário root (ou outro que tenha privilégios de administrador) pode mudar não só a sua própria senha como a senha de todos os outros usuários do sistema. Para isso, o comando passwd também é usado e pode ser acrescido de opções:
passwd usuário opções
Eis algumas das opções disponíveis (para conhecer as outras, pode-se digitar o comando man passwd em um terminal):
-e: faz com que a senha do usuário expire, forçando-o a fornecer uma nova combinação no próximo login;
-k: permite a alteração da senha somente se esta estiver expirada;
-x dias: faz com que a senha funcione apenas pela quantidade de dias informada. Depois disso, a senha expira e o usuário deve trocá-la;
-n dias: indica a quantidade mínima de dias que o usuário deve aguardar para trocar a senha;
-w dias: define a quantidade mínima de dias em que o usuário receberá o aviso de que sua senha precisa ser alterada;
-i: deixa a conta inativa, caso a senha tenha expirado;
-l: "tranca" a conta do usuário;
-u: desbloqueia uma conta que esteja "trancada";
-S: exibe o status da conta (note que a letra S deve estar em maiúscula).
Vamos a alguns exemplos para que você possa entender essas opções:
Suponha que você queira que a senha do usuário marvin expire após 30 dias. O comando é:
passwd marvin -x 30
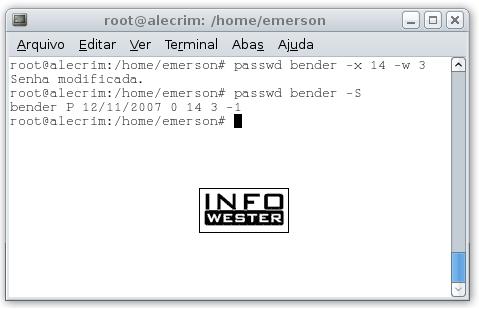
Suponha, agora, que você queira que a senha do usuário bender expire após 14 dias e exiba uma mensagem de que é necessário trocar a senha três dias antes da data limite. O comando será o seguinte:
passwd bender -x 14 -w 3
Agora, vamos supor que você queira saber do status do usuário bender, para confirmar as alterações. Eis o comando:
passwd bender -S
O resultado exibido neste exemplo é:
bender P 12/11/2007 0 14 3 -1
A letra P acima informa que o usuário bender tem senha. Se não tivesse, no lugar de P estariam as letras NP. Se a conta do usuário estivesse bloqueada, apareceria a letra L. Por sua vez, a data que aparece na seqüência (no formato mês/dia/ano) informa a última alteração de senha que houve. As próximas quatro informações indicam, respectivamente, o período mínimo de utilização da senha, o período máximo (lembra que você definiu esse período com sendo de 14 dias?), o período de alerta (que você informou como sendo de 3 dias) e, por fim, o período de inatividade (quando não há inatividade, o resultado é -1).
Como já informado antes, o GNU/Linux usa o arquivo /etc/shadow para lidar com as senhas de usuários. As informações desse arquivo têm o seguinte padrão (usando como exemplo os dados do usuário toad):
toad:$1$O48MNVt9$08BBOTqV0cr2LtKtMXtAY1:13849:0:99999:7:::
Assim como acontece no arquivo /etc/passwd, as informações do arquivo /etc/shadow são separadas por : (dois pontos). No caso acima, aparece o nome do usuário (toad), a senha criptografada (é por que isso que há esse monte de caracteres sem sentido), a data da última mudança (13849), a quantidade mínima de dias que o usuário deve esperar para mudar a sua senha (0), a quantidade máxima de dias para a alteração de senha ser feita (99999) e a quantidade de dias restantes à data de expiração que o sistema operacional deve esperar para exibir alertas de mudança de senha (7). Os demais campos (que estão em branco) são destinados à informações de expiração de conta, mas dificilmente são usados.
Você pode ter se perguntado sobre o motivo das datas serem representadas por um único número, como o valor 13849, acima. Essa formato indica a quantidade de dias que já se passou desde 1 de janeiro de 1970.
Gerenciando grupos
Lidar com grupos no GNU/Linux é tarefa muito semelhante ao trabalho com usuários. Veja os principais comandos disponíveis:addgroup grupo: funciona de maneira igual ao comando adduser (inclusive algumas opções são as mesmas), no entanto, obviamente, cria grupos ao invés de usuários;
groupdel grupo: serve para eliminar grupos do sistema;
newgrp - grupo: com este comando é possível mudar o grupo efetivo do usuário, isto é, o grupo pertencente a ele, por um outro grupo do qual ele faz parte. Essa operação somente é executada caso o grupo tenha senha;
groups usuário: mostra os grupos dos quais um usuário faz parte. Se quiser, por exemplo, saber os grupos do usuário gandalf, basta digitar em um terminal:
groups gandalf
As informações dos grupos são armazenadas no arquivo /etc/groups. Esse arquivo também indica quais usuários pertencem aos grupos existentes. Cada grupo contém uma linha com essas informações. Vamos analisar a seguinte linha de um arquivo /etc/groups para entender melhor como isso funciona:
infowester:x:1002:wester,toad,marvin
Assim como nos arquivos /etc/passwd e /etc/shadow, os campos da linha são separados por : (dois pontos). No exemplo acima, o primeiro campo indica o nome do grupo (infowester). O segundo campo informa a senha (sim, é possível definir senhas para grupos, embora raramente isso seja feito). Neste caso, usa-se x para indicar a ausência de senha. O terceiro campo informa o GID do grupo (1002) e, por fim, o quarto campo informa quais são os usuários pertencentes a esse grupo. Note que, neste exemplo, os usuários wester, toad e marvin fazem parte do grupo infowester. A lista de usuários deve ser separada por vírgulas, sem espaço entre os nomes.
No que se refere a este assunto, é possível que encontre grupos em seu sistema que você não lembra de ter criado. Suponha, por exemplo, que você digitou o comando groups lestat para saber quais os grupos dos quais participa o usuário lestat, e o resultado foi o seguinte:
lestat : lestat adm cdrom floppy audio video scanner lpadmin powerdev
Note que o usuário lestat participa de vários grupos, sendo um deles o seu grupo principal, que leva o seu nome. Mas, de onde surgiram os demais? O GNU/Linux possui alguns grupos considerados "padrão", isto é, grupos que servem para permitir que o usuário execute determinadas tarefas. A quantidade e as finalidades dos grupos podem variar de acordo com a distribuição GNU/Linux utilizada e a sua configuração. Eis alguns grupos bastante comuns:
cdrom: grupo para utilização de unidades de CD/DVD;
audio: grupo para acesso aos recursos de áudio do computador;
video: grupo para acesso aos recursos de vídeo do computador;
floppy: grupo para utilização da unidade de disquete;
adm: grupo para acesso de recursos administrativos.
Alterando informações dos usuários
Se você pode criar e apagar contas de usuários, pode também alterá-las. Isso é feito facilmente com o comando usermod, cujo funcionamento é semelhante ao comando adduser:usermod opções usuário
Eis algumas de suas opções:
usermod -d diretório usuário: altera o diretório "home" do usuário. Adicione -m no final para mover o conteúdo da pasta anterior para a nova. Por exemplo:
usermod -d /financeiro -m peterpan
usermod -e data usuário: define a data de expiração da conta do usuário. Em geral, a data é fornecida no esquema ano/mês/dia (aaaa-mm-dd). Por exemplo:
usermod -e 2008-10-28 galadriel
usermod -l novo_nome usuário: altera o nome do login do usuário. No exemplo abaixo, o usuário peterparker teve seu nome alterado para spiderman:
usermod -l spiderman peterparker
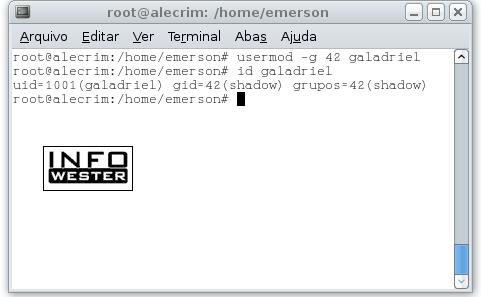
usermod -g grupo número usuário: altera o GID do grupo principal do usuário. Por exemplo:
usermod -g 42 galadriel
usermod -s shell usuário: altera o shell do usuário;
usermod -u número usuário: altera o UID da conta do usuário.
Comandos adicionais
O GNU/Linux ainda conta com vários outros comandos que lhe ajudam a gerenciar e obter informações de usuários e grupos. Veja alguns:logname: mostra o nome do seu usuário;
users: mostra os usuários que estão conectados ao sistema no momento;
id: mostra dados da identificação do usuário. Eis algumas opções:
id usuário: exibe os grupos (e seus respectivos GIDs) dos quais o usuário faz parte;
id -g usuário: mostra o GID do grupo do usuário;
id -G usuário: exibe o GID de todos os grupos do usuário (nome que a letra G fica em caixa alta);
id -u usuário: indica o UID do usuário.
finger usuário: mostra informações detalhadas do usuário. Se o comando for digitado isoladamente (ou seja, somente finger), o sistema exibe todos os usuários que estão conectados no sistema operacional no momento;
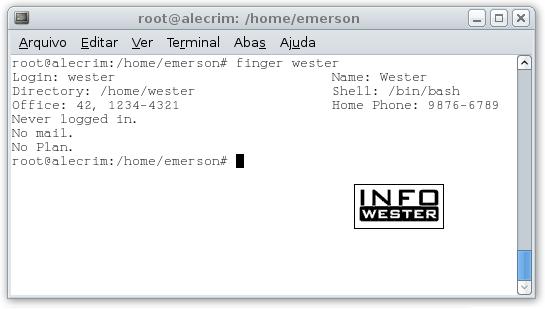
chfn usuário: comando para mudar as informações adicionais do usuário (nome completo, telefone, etc).
last: o comando last é bastante interessante e útil, pois mostra os últimos usuários que estiveram logados no sistema, os terminais usados por eles para se conectar, o hostname (quando a conexão é feita remotamente), as datas e os horários de utilização do computador, assim como o tempo de permanência no sistema. Esses dados geralmente são obtidos do arquivo de logs /var/log/wtmp. O last também possui opções. Veja algumas:
last -n número: mostra apenas as últimas linhas do log. Para definir a quantidade de linhas, substitua número pelo valor desejado. Por exemplo:
last -n 10
last -x: mostra os dados de desligamento do sistema, assim como informações do nível de execução;
last -R: faz com que o comando não exiba os hostnames (note que a letra R fica em caixa alta);
last -a: faz com que os hostnames sejam exibidos apenas na última coluna.
Fonte: http://www.infowester.com/usuarioslinux.php
segunda-feira, 28 de novembro de 2011
Excel: Aprenda a criar tabelas dinâmicas
O
programa Microsoft Excel é bastante utilizado por diversos tipos de
pessoas e para variadas finalidades. Com ele, é possível criar simples
tabelas de horários escolares, por exemplo, até mesmo complexos bancos
de dados.
Contudo, no caso dos bancos de dados, quanto maior for o seu tamanho e a quantidade de informações contidas, mais difícil será para gerenciá-lo e até mesmo para realizar buscas por dados.
Neste caso, você poderá criar tabelas dinâmicas para facilitar a comparação, elaboração de relatórios e acesso aos dados de suas planilhas. Além disso, com ela ficará mais fácil também a reordenação de linhas e colunas em suas tabelas. O Baixaki irá ensinar agora, através de um tutorial simples de seguir, como criar este tipo de planilhas. Então, mãos à obra!
Criando tabelas dinâmicas
O primeiro passo é abrir o arquivo com a tabela que você deseja transformar em tabela dinâmica.
 Selecione o campo da tabela com o mouse.
Selecione o campo da tabela com o mouse.
 Agora, clique na guia Inserir e depois em Tabela Dinâmica
e então surgirá uma nova janela em sua tela. Nela, você poderá alterar
os campos que farão parte de sua nova tabela e também definir o local
aonde ela será criada (na mesma ou em uma nova planilha).
Agora, clique na guia Inserir e depois em Tabela Dinâmica
e então surgirá uma nova janela em sua tela. Nela, você poderá alterar
os campos que farão parte de sua nova tabela e também definir o local
aonde ela será criada (na mesma ou em uma nova planilha).
 Além dos campos em sua própria planilha, é possível também selecionar fontes externas, para isso, clique em Usar uma fonte de dados externa e então escolha a partir de onde virão os dados de sua nova tabela dinâmica. Depois disso, clique em OK.
Além dos campos em sua própria planilha, é possível também selecionar fontes externas, para isso, clique em Usar uma fonte de dados externa e então escolha a partir de onde virão os dados de sua nova tabela dinâmica. Depois disso, clique em OK.
 Sua tabela dinâmica está pronta. A partir de agora, para acessar os
valores e dados, clique sobre a tabela e então selecione tudo o que
deseja analisar.
Sua tabela dinâmica está pronta. A partir de agora, para acessar os
valores e dados, clique sobre a tabela e então selecione tudo o que
deseja analisar.
 Com este tipo de tabela, você poderá comparar dados facilmente, como
no exemplo abaixo, quando foram selecionados os dados de somente três
pessoas:
Com este tipo de tabela, você poderá comparar dados facilmente, como
no exemplo abaixo, quando foram selecionados os dados de somente três
pessoas:
 Ainda na barra do lado direito, você poderá mover os dados entre os campos Filtro de Relatórios, Rótulos de Coluna, Rótulos de Linha e Valores.
Ainda na barra do lado direito, você poderá mover os dados entre os campos Filtro de Relatórios, Rótulos de Coluna, Rótulos de Linha e Valores.
 Acessando as opções da tabela dinâmica (Tabela Dinâmica > Opções > Opções), você poderá alterar algumas configurações de sua planilha, como impressão, definições de exibição, layout, filtros e dados.
Acessando as opções da tabela dinâmica (Tabela Dinâmica > Opções > Opções), você poderá alterar algumas configurações de sua planilha, como impressão, definições de exibição, layout, filtros e dados.
 Adicionando filtros
Adicionando filtros
Para melhor analisar os dados, você pode adicionar filtros para poder reduzir a visualização de dados a algo mais específico. Para isso, clique sobre a guia Rótulos de Linha para que seja aberto o seu menu, depois vá em Filtro de Valores e escolha o tipo de filtro que deseja aplicar.
 Veja um exemplo com o filtro É Maior do que aplicado com o valor 140.000:
Veja um exemplo com o filtro É Maior do que aplicado com o valor 140.000:
 Outro tipo de filtros são os Filtros de Rótulos,
estes relativos aos rótulos da sua tabela. No nosso exemplo, os rótulos
são os meses. Esta função também será bem útil no caso de tabelas com um
grando número de dados e informações.
Outro tipo de filtros são os Filtros de Rótulos,
estes relativos aos rótulos da sua tabela. No nosso exemplo, os rótulos
são os meses. Esta função também será bem útil no caso de tabelas com um
grando número de dados e informações.
Você pode ainda utilizar seus próprios dados como filtros para comparação na tabela. Por exemplo, arraste qualquer um dos dados da aba direita para o campo Filtro de Relatório e então ele aparecerá em cima da sua tabela.
 Clique para abrir sua guia e então selecione o valor que deseja
utilizar como referência. Desta forma, você pode selecionar um ou vários
itens (no caso de nosso exemplo, meses) para filtrar e comparar com os
demais dados informados na tabela.
Clique para abrir sua guia e então selecione o valor que deseja
utilizar como referência. Desta forma, você pode selecionar um ou vários
itens (no caso de nosso exemplo, meses) para filtrar e comparar com os
demais dados informados na tabela.
 Considerações
Considerações
Apesar de nosso exemplo ser uma tabela pequena, este recurso é bastante interessante para bancos de dados com muitas informações, onde a simples visualização é prejudicada pela grande quantidade de informações. De qualquer maneira, este recurso é indicado para qualquer um que queira gerar relatórios de maneira eficiente e precisa, sem que para isso tenha muito trabalho.
Contudo, no caso dos bancos de dados, quanto maior for o seu tamanho e a quantidade de informações contidas, mais difícil será para gerenciá-lo e até mesmo para realizar buscas por dados.
Neste caso, você poderá criar tabelas dinâmicas para facilitar a comparação, elaboração de relatórios e acesso aos dados de suas planilhas. Além disso, com ela ficará mais fácil também a reordenação de linhas e colunas em suas tabelas. O Baixaki irá ensinar agora, através de um tutorial simples de seguir, como criar este tipo de planilhas. Então, mãos à obra!
Criando tabelas dinâmicas
O primeiro passo é abrir o arquivo com a tabela que você deseja transformar em tabela dinâmica.
Para melhor analisar os dados, você pode adicionar filtros para poder reduzir a visualização de dados a algo mais específico. Para isso, clique sobre a guia Rótulos de Linha para que seja aberto o seu menu, depois vá em Filtro de Valores e escolha o tipo de filtro que deseja aplicar.
Você pode ainda utilizar seus próprios dados como filtros para comparação na tabela. Por exemplo, arraste qualquer um dos dados da aba direita para o campo Filtro de Relatório e então ele aparecerá em cima da sua tabela.
Apesar de nosso exemplo ser uma tabela pequena, este recurso é bastante interessante para bancos de dados com muitas informações, onde a simples visualização é prejudicada pela grande quantidade de informações. De qualquer maneira, este recurso é indicado para qualquer um que queira gerar relatórios de maneira eficiente e precisa, sem que para isso tenha muito trabalho.
Fonte: http://www.tecmundo.com.br/1056-excel-aprenda-a-criar-tabelas-dinamicas.htm
terça-feira, 15 de novembro de 2011
Curso Oracle 11g - Lesson 7 - Programação Part2
--Lesson 7
--Usando expressoes regulares
--REGEXP_LIKE
--usando duas condições no like
select first_name, last_name
from employees
where regexp_like (first_name, '^Ste(v|ph)en$');
--REGEXP_REPLACE
--Substitui todos os caracteres correspondentes por outro
select phone_number, regexp_replace(phone_number, '\.','-') as phone, --substitui todos que econtrar
regexp_replace(phone_number, '^6','-') as phone2, --substitui o primeiro correspondente que encontar
regexp_replace(phone_number, '$4','-') as phone3, --substitui o último correspondente que encontar
regexp_replace(phone_number, '(5|3|1)','-') as phone4 --todos correspondetes
from employees;
--REGEXP_INSTR
--acha a primeira posição do caracter alpha
SELECT street_address,
REGEXP_INSTR(street_address,'[[:alpha:]]') AS First_Alpha_Position
FROM locations;
--REGEXP_SUBSTR
--entra um determinado caracter e traz o restante
SELECT street_address,
REGEXP_SUBSTR(street_address , ' [^ ]+ ') AS Road --procura o espaço em branco e traz a palavra até o próximo espaço em branco
-- o sina de " + " é o indicador para repetir a expressão
FROM locations;
--Subexpressions
--exemplo procurar uma seguencia de DNA
SELECT REGEXP_INSTR('ccacctttccctccactcctcacgttctcacctgtaaagcgtccctccctcatccccatgcccccttaccctgcagggtagagtaggctagaaaccagagagctccaagctccatctgtggagaggtgccatccttgggctgcagagagaggagaatttgccccaaagctgcctgcagagcttcaccacccttagtctcacaaagccttgagttcatagcatttcttgagttttcaccctgcccagcaggacactgcagcacccaaagggcttcccaggagtagggttgccctcaagaggctcttgggtctgatggccacatcctggaattgttttcaagttgatggtcacagccctgaggcatgtaggggcgtggggatgcgctctgctctgctctcctctcctgaacccctgaaccctctggctaccccagagcacttagagccag',
'(gtc(tcac)(aaag))',
1, 1, 0, 'i',
1) "Position"
FROM dual;
--REGEXP_COUNT
--quantas vezes aparece uma determinada expressão
SELECT REGEXP_COUNT( 'ccacctttccctccactcctcacgttctcacctgtaaagcgtccctccctcatccccatgcccccttaccctgcag ggtagagtaggctagaaaccagagagctccaagctccatctgtggagaggtgccatccttgggctgcagagagaggagaatttgccccaaagctgcctgcagagcttcaccacccttagtctcacaaagccttgagttcatagcatttcttgagttttcaccctgcccagcaggacactgcagcacccaaagggcttcccaggagtagggttgccctcaagaggctcttgggtctgatggccacatcctggaattgttttcaagttgatggtcacagccctgaggcatgtaggggcgtggggatgcgctctgctctgctctcctctcctgaacccctgaaccctctggctaccccagagcacttagagccag', 'gtc') AS Count
FROM dual;
--Check Constraints
ALTER TABLE employees
ADD CONSTRAINT email_addr
CHECK(REGEXP_LIKE(email,'@')) NOVALIDATE;
INSERT INTO employees VALUES
(500,'Christian','Patel','ChrisP2creme.com',
1234567890,'12-Jan-2004','HR_REP',2000,null,102,40);
select * from employees;
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
--Usando expressoes regulares
--REGEXP_LIKE
--usando duas condições no like
select first_name, last_name
from employees
where regexp_like (first_name, '^Ste(v|ph)en$');
--REGEXP_REPLACE
--Substitui todos os caracteres correspondentes por outro
select phone_number, regexp_replace(phone_number, '\.','-') as phone, --substitui todos que econtrar
regexp_replace(phone_number, '^6','-') as phone2, --substitui o primeiro correspondente que encontar
regexp_replace(phone_number, '$4','-') as phone3, --substitui o último correspondente que encontar
regexp_replace(phone_number, '(5|3|1)','-') as phone4 --todos correspondetes
from employees;
--REGEXP_INSTR
--acha a primeira posição do caracter alpha
SELECT street_address,
REGEXP_INSTR(street_address,'[[:alpha:]]') AS First_Alpha_Position
FROM locations;
--REGEXP_SUBSTR
--entra um determinado caracter e traz o restante
SELECT street_address,
REGEXP_SUBSTR(street_address , ' [^ ]+ ') AS Road --procura o espaço em branco e traz a palavra até o próximo espaço em branco
-- o sina de " + " é o indicador para repetir a expressão
FROM locations;
--Subexpressions
--exemplo procurar uma seguencia de DNA
SELECT REGEXP_INSTR('ccacctttccctccactcctcacgttctcacctgtaaagcgtccctccctcatccccatgcccccttaccctgcagggtagagtaggctagaaaccagagagctccaagctccatctgtggagaggtgccatccttgggctgcagagagaggagaatttgccccaaagctgcctgcagagcttcaccacccttagtctcacaaagccttgagttcatagcatttcttgagttttcaccctgcccagcaggacactgcagcacccaaagggcttcccaggagtagggttgccctcaagaggctcttgggtctgatggccacatcctggaattgttttcaagttgatggtcacagccctgaggcatgtaggggcgtggggatgcgctctgctctgctctcctctcctgaacccctgaaccctctggctaccccagagcacttagagccag',
'(gtc(tcac)(aaag))',
1, 1, 0, 'i',
1) "Position"
FROM dual;
--REGEXP_COUNT
--quantas vezes aparece uma determinada expressão
SELECT REGEXP_COUNT( 'ccacctttccctccactcctcacgttctcacctgtaaagcgtccctccctcatccccatgcccccttaccctgcag ggtagagtaggctagaaaccagagagctccaagctccatctgtggagaggtgccatccttgggctgcagagagaggagaatttgccccaaagctgcctgcagagcttcaccacccttagtctcacaaagccttgagttcatagcatttcttgagttttcaccctgcccagcaggacactgcagcacccaaagggcttcccaggagtagggttgccctcaagaggctcttgggtctgatggccacatcctggaattgttttcaagttgatggtcacagccctgaggcatgtaggggcgtggggatgcgctctgctctgctctcctctcctgaacccctgaaccctctggctaccccagagcacttagagccag', 'gtc') AS Count
FROM dual;
--Check Constraints
ALTER TABLE employees
ADD CONSTRAINT email_addr
CHECK(REGEXP_LIKE(email,'@')) NOVALIDATE;
INSERT INTO employees VALUES
(500,'Christian','Patel','ChrisP2creme.com',
1234567890,'12-Jan-2004','HR_REP',2000,null,102,40);
select * from employees;
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
Curso Oracle 11g - Lesson 6 - Programação Part2
--Lesson 6
--SubQuery (PAIRWISE COMPARISON SUBQUERY)
--comparação com duas colunas
Select last_name, manager_id, department_id
from employees
where first_name = 'John';
Select first_name, last_name, manager_id, department_id
from employees
where manager_id = 108 and department_id = 100;
Select first_name, last_name, manager_id, department_id
from employees
where (manager_id = 108 and department_id = 100) or
(manager_id = 123 and department_id = 50);
Select first_name, last_name, manager_id, department_id
from employees
where manager_id in
(select manager_id from employees where first_name = 'John')
and department_id in
(select department_id from employees where first_name = 'John')
and first_name <> 'John';
--Com dois parametros
Select first_name, last_name, manager_id, department_id
from employees
where (manager_id,department_id) in
(select manager_id, department_id from employees where first_name = 'John');
Select *
from departments
where location_id = 1800;
Select employee_id, first_name,
case when department_id = 20 then 'canada' else 'usa' end
from employees;
Select employee_id, first_name,
case when department_id =
(select department_id from departments where location_id = 1800)
then 'canada' else 'usa' end
from employees;
--a mesma consulta sem subquery, melhor performance
Select employee_id, first_name,
case when location_id = 1800 then 'canada' else 'usa' end
from employees e
left join departments d
on(e.department_id = d.department_id);
--Correlated Subquery
Select first_name, department_id,
( select department_name
from departments
where department_id = e.department_id)
from employees e;
--Todos que ganha salario maior que a média
select avg(salary), department_id from employees group by department_id;
select first_name, salary,(select avg(salary) from employees
where department_id = e.department_id)
from employees e
where salary > (select avg(salary) from employees
where department_id = e.department_id);
---WITH CLAUSE
--Cria-se um View temporaria, apenas em tempo de execução
With
media_salario as
(select department_id, round(avg(salary),2) as media
from employees
group by department_id)
select first_name, e.department_id, salary, media
from employees e inner join media_salario m
on(e.department_id = m.department_id)
where salary > media;
--EXISTS
--select normal
select employee_id, first_name, job_id
from employees e
where employee_id in (select manager_id from employees);
--usando EXISTS
select employee_id, first_name, job_id
from employees e
where exists (Select 'qualquer coisa'
from employees
where manager_id = e.employee_id);
--NOT EXISTS
--select normal
select department_id, department_name
from departments
where department_id not in (select department_id
from employees
where department_id is not null );
--outro jeito
select d.department_id, department_name
from departments d
left join employees e
on (d.department_id = e.department_id)
where e.department_id is null;
--usando NOT EXISTS
select d.department_id, department_name
from departments d
where not exists ( select 'qualquer coisa'
from employees e
where e.department_id = d.department_id);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
--SubQuery (PAIRWISE COMPARISON SUBQUERY)
--comparação com duas colunas
Select last_name, manager_id, department_id
from employees
where first_name = 'John';
Select first_name, last_name, manager_id, department_id
from employees
where manager_id = 108 and department_id = 100;
Select first_name, last_name, manager_id, department_id
from employees
where (manager_id = 108 and department_id = 100) or
(manager_id = 123 and department_id = 50);
Select first_name, last_name, manager_id, department_id
from employees
where manager_id in
(select manager_id from employees where first_name = 'John')
and department_id in
(select department_id from employees where first_name = 'John')
and first_name <> 'John';
--Com dois parametros
Select first_name, last_name, manager_id, department_id
from employees
where (manager_id,department_id) in
(select manager_id, department_id from employees where first_name = 'John');
Select *
from departments
where location_id = 1800;
Select employee_id, first_name,
case when department_id = 20 then 'canada' else 'usa' end
from employees;
Select employee_id, first_name,
case when department_id =
(select department_id from departments where location_id = 1800)
then 'canada' else 'usa' end
from employees;
--a mesma consulta sem subquery, melhor performance
Select employee_id, first_name,
case when location_id = 1800 then 'canada' else 'usa' end
from employees e
left join departments d
on(e.department_id = d.department_id);
--Correlated Subquery
Select first_name, department_id,
( select department_name
from departments
where department_id = e.department_id)
from employees e;
--Todos que ganha salario maior que a média
select avg(salary), department_id from employees group by department_id;
select first_name, salary,(select avg(salary) from employees
where department_id = e.department_id)
from employees e
where salary > (select avg(salary) from employees
where department_id = e.department_id);
---WITH CLAUSE
--Cria-se um View temporaria, apenas em tempo de execução
With
media_salario as
(select department_id, round(avg(salary),2) as media
from employees
group by department_id)
select first_name, e.department_id, salary, media
from employees e inner join media_salario m
on(e.department_id = m.department_id)
where salary > media;
--EXISTS
--select normal
select employee_id, first_name, job_id
from employees e
where employee_id in (select manager_id from employees);
--usando EXISTS
select employee_id, first_name, job_id
from employees e
where exists (Select 'qualquer coisa'
from employees
where manager_id = e.employee_id);
--NOT EXISTS
--select normal
select department_id, department_name
from departments
where department_id not in (select department_id
from employees
where department_id is not null );
--outro jeito
select d.department_id, department_name
from departments d
left join employees e
on (d.department_id = e.department_id)
where e.department_id is null;
--usando NOT EXISTS
select d.department_id, department_name
from departments d
where not exists ( select 'qualquer coisa'
from employees e
where e.department_id = d.department_id);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
Curso Oracle 11g - Lesson 5 - Programação Part2
--lesson 5
--Alterar o fuso horário
alter session set time_zone = '-5:00';
--mostrar o fuso horário
select dbtimezone,sessiontimezone, current_date, current_timestamp,
localtimestamp
from dual;
Create table tab_datas (
data1 date,
data2 timestamp,
data3 timestamp with time zone,
data4 timestamp with local time zone
);
alter session set time_zone = '-3:00';
insert into tab_datas values
(current_date, current_date, current_date, current_date);
select * from tab_datas;
---Interval
--Conta com intervalos de anos e meses
create table warranty
(prod_id number,
warranty_time interval year(3) to month);
insert into warranty values (123, interval '8' month);
insert into warranty values (155, interval '200' year(3));
insert into warranty values (678, '200-11');
select * from warranty;
select current_date + interval '8' month from warranty;
select current_date, warranty_time, current_date + warranty_time from warranty;
create table garantia
(produto number(6),
data_compra date,
garantia_meses number(2));
insert into garantia values(1,'15/09/2011', 18);
select * from garantia;
select data_compra, garantia_meses, ADD_MONTHS(data_compra,garantia_meses)
from garantia;
--EXTRACT
--Extrair ano ou mês
select * from employees;
select last_name,
extract(year from sysdate) - extract(year from hire_date),
extract(month from hire_date)
from employees
order by 2 desc;
select extract(month from hire_date), count(*)
from employees
group by extract(month from hire_date);
--TZ_OFFSET
--Mostra fuso horário de uma região especifica
select sessiontimezone, current_date from dual;
select tz_offset('America/Sao_Paulo') from dual;
--Mostra todos os fusos horário
select * from v$timezone_names;
--FROM_TZ
--Mostra uma data/horário conforme o fuso horário escolhido
select from_tz(timestamp '2000-07-12 08:00:00', 'Australia/North')
from dual;
--TO_TIMESTAMP
--transformar explicitamente um texto em data/hora
Select to_timestamp('10-11-12 08:00:00')
from dual;
--TO_YMINTERVAL
--soma ano e mes em uma data
--TO_DSINTERVAL
--soma dias, horas, minutos e segundos
select hire_date, hire_date + to_yminterval('1-2') as hire_date,
hire_date + to_dsinterval('100 10:00:00') as hire_date2
from employees;
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
--Alterar o fuso horário
alter session set time_zone = '-5:00';
--mostrar o fuso horário
select dbtimezone,sessiontimezone, current_date, current_timestamp,
localtimestamp
from dual;
Create table tab_datas (
data1 date,
data2 timestamp,
data3 timestamp with time zone,
data4 timestamp with local time zone
);
alter session set time_zone = '-3:00';
insert into tab_datas values
(current_date, current_date, current_date, current_date);
select * from tab_datas;
---Interval
--Conta com intervalos de anos e meses
create table warranty
(prod_id number,
warranty_time interval year(3) to month);
insert into warranty values (123, interval '8' month);
insert into warranty values (155, interval '200' year(3));
insert into warranty values (678, '200-11');
select * from warranty;
select current_date + interval '8' month from warranty;
select current_date, warranty_time, current_date + warranty_time from warranty;
create table garantia
(produto number(6),
data_compra date,
garantia_meses number(2));
insert into garantia values(1,'15/09/2011', 18);
select * from garantia;
select data_compra, garantia_meses, ADD_MONTHS(data_compra,garantia_meses)
from garantia;
--EXTRACT
--Extrair ano ou mês
select * from employees;
select last_name,
extract(year from sysdate) - extract(year from hire_date),
extract(month from hire_date)
from employees
order by 2 desc;
select extract(month from hire_date), count(*)
from employees
group by extract(month from hire_date);
--TZ_OFFSET
--Mostra fuso horário de uma região especifica
select sessiontimezone, current_date from dual;
select tz_offset('America/Sao_Paulo') from dual;
--Mostra todos os fusos horário
select * from v$timezone_names;
--FROM_TZ
--Mostra uma data/horário conforme o fuso horário escolhido
select from_tz(timestamp '2000-07-12 08:00:00', 'Australia/North')
from dual;
--TO_TIMESTAMP
--transformar explicitamente um texto em data/hora
Select to_timestamp('10-11-12 08:00:00')
from dual;
--TO_YMINTERVAL
--soma ano e mes em uma data
--TO_DSINTERVAL
--soma dias, horas, minutos e segundos
select hire_date, hire_date + to_yminterval('1-2') as hire_date,
hire_date + to_dsinterval('100 10:00:00') as hire_date2
from employees;
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
quinta-feira, 3 de novembro de 2011
Curso Oracle 11g - Lesson 4 - Programação Part2
--Lesson 04
--Manipulação de dados
--Primeiro criar as tabelas
--Unconditional INSERT ALL
Create table sal_history
(empid number(4),
hiredate date,
sal number(8,2),
jobid varchar2(10));
create table mgr_history
(empid number(4),
mgr number(4),
sal number(8,2));
Insert all
Into sal_history values (empid, hiredate, sal, jobid)
Into mgr_history values (empid, mgr, sal)
Select employee_id empid, hire_date hiredate, salary sal, manager_id mgr, job_id jobid
from employees;
select * from sal_history;
select * from mgr_history;
--Conditional INSERT ALL
Create table emp_history
(empid number(4),
hiredate date,
sal number(8,2));
create table emp_sales
(empid number(4),
comm number(2,2),
sal number(8,2));
Insert All
When hiredate < '01-01-2005' then
Into emp_history values (empid, hiredate, sal)
When comm is not null then
Into emp_sales values (empid, comm, sal)
Select employee_id empid, hire_date hiredate, salary sal, commission_pct comm
From employees;
--Insert First
--É como o exemplo acima, mas atende a primeira condição não verifica as demais
--Pivoting Insert
--MERGE
Create table emp_new (
emp_id number(6),
first_name varchar2(40),
salary number(8,2));
Insert Into emp_new values(100, 'Anderon', 28000);
commit;
select * from emp_new;
alter table emp_new modify emp_id primary key;
insert into emp_new (emp_id, first_name, salary)
select employee_id, first_name, salary
from employees;
Merge Into Emp_new n
Using (Select employee_id, first_name, salary, commission_pct from employees) e
on (n.emp_id = e.employee_id)
when matched then
update set
n.first_name = e.first_name,
n.salary = e.salary
delete where (e.commission_pct is not null)
When not matched then
Insert Values (e.employee_id, e.first_name, e.salary);
/*
Ele olha o emp_new, existe um valor correspondente, então substitui pelo registro da tabela employees;
Caso não hava correspondente, insere os registros da tabela employees;
*/
select * from emp_new;
---Flashback UPDATE
--Verificação das modificações, com hora inicial e final. Mostrando as informações comitadas
--Obs.: por padrão essa informação fica durante 15 minutos
select employee_id, salary
from employees
where employee_id in (100,101);
update employees
set salary = salary * 1.01
where employee_id in (100,101);
commit;
select employee_id, salary, versions_starttime, versions_endtime
from employees
versions between scn minvalue and maxvalue
where employee_id in (100,101);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
--Manipulação de dados
--Primeiro criar as tabelas
--Unconditional INSERT ALL
Create table sal_history
(empid number(4),
hiredate date,
sal number(8,2),
jobid varchar2(10));
create table mgr_history
(empid number(4),
mgr number(4),
sal number(8,2));
Insert all
Into sal_history values (empid, hiredate, sal, jobid)
Into mgr_history values (empid, mgr, sal)
Select employee_id empid, hire_date hiredate, salary sal, manager_id mgr, job_id jobid
from employees;
select * from sal_history;
select * from mgr_history;
--Conditional INSERT ALL
Create table emp_history
(empid number(4),
hiredate date,
sal number(8,2));
create table emp_sales
(empid number(4),
comm number(2,2),
sal number(8,2));
Insert All
When hiredate < '01-01-2005' then
Into emp_history values (empid, hiredate, sal)
When comm is not null then
Into emp_sales values (empid, comm, sal)
Select employee_id empid, hire_date hiredate, salary sal, commission_pct comm
From employees;
--Insert First
--É como o exemplo acima, mas atende a primeira condição não verifica as demais
--Pivoting Insert
--MERGE
Create table emp_new (
emp_id number(6),
first_name varchar2(40),
salary number(8,2));
Insert Into emp_new values(100, 'Anderon', 28000);
commit;
select * from emp_new;
alter table emp_new modify emp_id primary key;
insert into emp_new (emp_id, first_name, salary)
select employee_id, first_name, salary
from employees;
Merge Into Emp_new n
Using (Select employee_id, first_name, salary, commission_pct from employees) e
on (n.emp_id = e.employee_id)
when matched then
update set
n.first_name = e.first_name,
n.salary = e.salary
delete where (e.commission_pct is not null)
When not matched then
Insert Values (e.employee_id, e.first_name, e.salary);
/*
Ele olha o emp_new, existe um valor correspondente, então substitui pelo registro da tabela employees;
Caso não hava correspondente, insere os registros da tabela employees;
*/
select * from emp_new;
---Flashback UPDATE
--Verificação das modificações, com hora inicial e final. Mostrando as informações comitadas
--Obs.: por padrão essa informação fica durante 15 minutos
select employee_id, salary
from employees
where employee_id in (100,101);
update employees
set salary = salary * 1.01
where employee_id in (100,101);
commit;
select employee_id, salary, versions_starttime, versions_endtime
from employees
versions between scn minvalue and maxvalue
where employee_id in (100,101);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
Curso Oracle 11g - Lesson 3 - Programação Part2
--Lesson 3 - Tabelas de Sistema
Select *
from dictionary;
Select *
From user_tables;
Select *
From All_tables;
Select *
From dba_tables;
Select *
from user_objects
order by object_Type;
select * from user_indexes u
where u.index_name = 'SYS_C0011122';
select *
from user_tab_columns;
select *
from user_constraints;
select tab.table_name, null, com.comments, 1
from user_tables tab
join user_tab_comments com on (tab.table_name = com.table_name)
union
select tab.table_name, col.column_name, com.comments, 2
from user_tables tab
join user_tab_columns col on (tab.table_name = col.table_name)
join user_col_comments com on (col.column_name = com.column_name
and col.table_name = com.table_name);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
Select *
from dictionary;
Select *
From user_tables;
Select *
From All_tables;
Select *
From dba_tables;
Select *
from user_objects
order by object_Type;
select * from user_indexes u
where u.index_name = 'SYS_C0011122';
select *
from user_tab_columns;
select *
from user_constraints;
select tab.table_name, null, com.comments, 1
from user_tables tab
join user_tab_comments com on (tab.table_name = com.table_name)
union
select tab.table_name, col.column_name, com.comments, 2
from user_tables tab
join user_tab_columns col on (tab.table_name = col.table_name)
join user_col_comments com on (col.column_name = com.column_name
and col.table_name = com.table_name);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
Curso Oracle 11g - Lesson 2 - Programação Part2
--Lesson 02
--Alter table
Create table exemplo01 (
codigo number(6),
nome varchar2(50));
--adicionar coluna
alter table exemplo01
add (data_nascimento date);
desc exemplo01;
--modificar uma coluna existente
alter table exemplo01
modify (nome varchar2(70));
desc exemplo01;
--apagar uma coluna
alter table exemplo01
drop column data_nascimento;
desc exemplo01;
insert into exemplo01 values(1,'anderson');
alter table exemplo01
modify (nome varchar2(80) not null);
rollback;
-- Obs.: o alter table, faz commit automático
select * from exemplo01;
desc exemplo01;
alter table
add (data_nascimento date not null);
--como já tenho informação não posso adicionar o not null
alter table exemplo01
add (tipo number(2) default 1);
--no registro onde a coluna estava vazio, foi colocado o valor default
select * from exemplo01;
alter table exemplo01
add (tipo2 number(2) default 1 not null);
--adicionando o valor default funciona
select * from exemplo01;
alter table exemplo01
add (tipo3 number(2));
--assim ele adiciona o valor como sendo nulo
select * from exemplo01;
insert into exemplo01 values(2,'teste',2,default,5);
select * from exemplo01;
alter table exemplo01
modify (tipo3 number(2) default 3);
--o valor que esta gravado, não é alterado
select * from exemplo01;
--Desabilitar uma coluna para apagar em um momento mais propicio
alter table exemplo01
set unused(tipo3);
select * from exemplo01;
desc exemplo01;
alter table exemplo01
add (tipo3 number(2) default 3);
select * from user_unused_col_tabs;--Pra saber quantas colunas foram desbilitadas em tabelas que sou dono
select * from all_unused_col_tabs;--Pra saber quantas colunas foram desbilitadas em todas tabelas que tenho acesso
select * from dba_unused_col_tabs;--Pra saber quantas colunas foram desbilitadas em todas as tabelas do banco de dados
--Apagar a coluna desabilitada
alter table exemplo01
drop unused columns;
Alter table exemplo01
modify (codigo primary key);
Alter table exemplo01
modify (nome default 'abc'); --apenas adicionar as alterações
select * from exemplo01;
desc exemplo01;
create table exemplo02 (numero number(6));
create table exemplo03 (numero number(6));
alter table exemplo02
modify (numero primary key); --o oracle nomeia a constraint automaticamente
insert into exemplo02 values (1); --não permite valores dublicados
alter table exemplo03
add constraint exemplo03_numero_pk --constraint nomeada
primary key (numero)
deferrable initially deferred; --Com essa alteração ele permite valores duplicados na cheve primaria,
--para que possa validar os dados de uma importação por exemplo,
--mas ao dar commit, ele apresentará o erro, fazendo o rollback automatico.
insert into exemplo03 values (1);
select * from exempl
commit;
--Trazer todas as constrains com chave primaria
select * from user_constraints
where constraint_type = 'P'
order by table_name;
--Apagar coluna
Alter table exemplo01
Drop column codigo;
--Drop column codigo cascade coonstraints; -- caso haja relacionament, apaga também o relacioanmento
select * from exemplo01;
--Renomear uma coluna
Alter table exemplo01
Rename column tipo
to tipo1;
select * from exemplo01;
--Tabela de index do usuário
Select *
from user_indexes;
---Flashback
--Recuperar uma tabela deletada
select * from job_history;
drop table job_history;
select * from recyclebin;
select * from "BIN$EdiYkjS3RpSdZRSk6QV7Fg==$0";
Flashback table job_history to before drop;
select * from job_history;
----Teste
Create table Apagar (codigo number(6), nome varchar2(40));
drop table Apagar;
select * from recyclebin;
create table Apagar (codigo number(6), nome varchar2(40));
insert into Apagar values (1, 'abc');
commit;
select * from Apagar;
Drop table Apagar;
select * from recyclebin;
create table Apagar as select * from "BIN$qUwIHQOwS/ueyFtW3pZ1mQ==$0";
insert into Apagar values(2,'der');
commit;
select * from Apagar aa
left join "BIN$qUwIHQOwS/ueyFtW3pZ1mQ==$0" lixeira
on (aa.codigo = lixeira.codigo);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
--Alter table
Create table exemplo01 (
codigo number(6),
nome varchar2(50));
--adicionar coluna
alter table exemplo01
add (data_nascimento date);
desc exemplo01;
--modificar uma coluna existente
alter table exemplo01
modify (nome varchar2(70));
desc exemplo01;
--apagar uma coluna
alter table exemplo01
drop column data_nascimento;
desc exemplo01;
insert into exemplo01 values(1,'anderson');
alter table exemplo01
modify (nome varchar2(80) not null);
rollback;
-- Obs.: o alter table, faz commit automático
select * from exemplo01;
desc exemplo01;
alter table
add (data_nascimento date not null);
--como já tenho informação não posso adicionar o not null
alter table exemplo01
add (tipo number(2) default 1);
--no registro onde a coluna estava vazio, foi colocado o valor default
select * from exemplo01;
alter table exemplo01
add (tipo2 number(2) default 1 not null);
--adicionando o valor default funciona
select * from exemplo01;
alter table exemplo01
add (tipo3 number(2));
--assim ele adiciona o valor como sendo nulo
select * from exemplo01;
insert into exemplo01 values(2,'teste',2,default,5);
select * from exemplo01;
alter table exemplo01
modify (tipo3 number(2) default 3);
--o valor que esta gravado, não é alterado
select * from exemplo01;
--Desabilitar uma coluna para apagar em um momento mais propicio
alter table exemplo01
set unused(tipo3);
select * from exemplo01;
desc exemplo01;
alter table exemplo01
add (tipo3 number(2) default 3);
select * from user_unused_col_tabs;--Pra saber quantas colunas foram desbilitadas em tabelas que sou dono
select * from all_unused_col_tabs;--Pra saber quantas colunas foram desbilitadas em todas tabelas que tenho acesso
select * from dba_unused_col_tabs;--Pra saber quantas colunas foram desbilitadas em todas as tabelas do banco de dados
--Apagar a coluna desabilitada
alter table exemplo01
drop unused columns;
Alter table exemplo01
modify (codigo primary key);
Alter table exemplo01
modify (nome default 'abc'); --apenas adicionar as alterações
select * from exemplo01;
desc exemplo01;
create table exemplo02 (numero number(6));
create table exemplo03 (numero number(6));
alter table exemplo02
modify (numero primary key); --o oracle nomeia a constraint automaticamente
insert into exemplo02 values (1); --não permite valores dublicados
alter table exemplo03
add constraint exemplo03_numero_pk --constraint nomeada
primary key (numero)
deferrable initially deferred; --Com essa alteração ele permite valores duplicados na cheve primaria,
--para que possa validar os dados de uma importação por exemplo,
--mas ao dar commit, ele apresentará o erro, fazendo o rollback automatico.
insert into exemplo03 values (1);
select * from exempl
commit;
--Trazer todas as constrains com chave primaria
select * from user_constraints
where constraint_type = 'P'
order by table_name;
--Apagar coluna
Alter table exemplo01
Drop column codigo;
--Drop column codigo cascade coonstraints; -- caso haja relacionament, apaga também o relacioanmento
select * from exemplo01;
--Renomear uma coluna
Alter table exemplo01
Rename column tipo
to tipo1;
select * from exemplo01;
--Tabela de index do usuário
Select *
from user_indexes;
---Flashback
--Recuperar uma tabela deletada
select * from job_history;
drop table job_history;
select * from recyclebin;
select * from "BIN$EdiYkjS3RpSdZRSk6QV7Fg==$0";
Flashback table job_history to before drop;
select * from job_history;
----Teste
Create table Apagar (codigo number(6), nome varchar2(40));
drop table Apagar;
select * from recyclebin;
create table Apagar (codigo number(6), nome varchar2(40));
insert into Apagar values (1, 'abc');
commit;
select * from Apagar;
Drop table Apagar;
select * from recyclebin;
create table Apagar as select * from "BIN$qUwIHQOwS/ueyFtW3pZ1mQ==$0";
insert into Apagar values(2,'der');
commit;
select * from Apagar aa
left join "BIN$qUwIHQOwS/ueyFtW3pZ1mQ==$0" lixeira
on (aa.codigo = lixeira.codigo);
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
Curso Oracle 11g - Lesson 1 - Programação Part2
--Lesson 1 - Segunda Parte
--Controlling User Access
Create User Anderson
Identified by Oracle;
--conectar-se no SQLPLUS e rodar o mesmo script
sqlplus / as sysdba
--conectar-se como anderson pelo sqlplus
sqlplus anderson/oracle as sysdba
--Mesmo não ter adicionado permissões para esse usuário, posso criar tabelas para esse usuário
Create Table Anderson.Teste (codigo number(6));
--Conceder as permissões ao usuário
Grant create session
To Anderson;
--Criação de Roles (conjunto de permissões)
Create Role manager;
--Conceder as permissões para as regras
Grant create table, create view
to manager;
--Adicionar o usuário a Role
Grant manager to Anderson;
--Mudar senha
Alter User Anderson
Identified by senha;
--Conceder acessos a objetos a um usuário
Grant select
on hr.regions
to manager; --podia ser direto para o usuário também
--Remover privilegios
Revoke select
on hr.regions
from manager;
--apagar usuário
drop user Teste;
--Exemplo
--Criar um novo usuário
Create User senac
Identified by senac;
Grant create session
to senac;
Create table senac.numeros (codigo number(6));
Insert into senac.numeros values(1); --O usuário senac não tem cota em disco, por isso não consegue fazer o insert
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
--Controlling User Access
Create User Anderson
Identified by Oracle;
--conectar-se no SQLPLUS e rodar o mesmo script
sqlplus / as sysdba
--conectar-se como anderson pelo sqlplus
sqlplus anderson/oracle as sysdba
--Mesmo não ter adicionado permissões para esse usuário, posso criar tabelas para esse usuário
Create Table Anderson.Teste (codigo number(6));
--Conceder as permissões ao usuário
Grant create session
To Anderson;
--Criação de Roles (conjunto de permissões)
Create Role manager;
--Conceder as permissões para as regras
Grant create table, create view
to manager;
--Adicionar o usuário a Role
Grant manager to Anderson;
--Mudar senha
Alter User Anderson
Identified by senha;
--Conceder acessos a objetos a um usuário
Grant select
on hr.regions
to manager; --podia ser direto para o usuário também
--Remover privilegios
Revoke select
on hr.regions
from manager;
--apagar usuário
drop user Teste;
--Exemplo
--Criar um novo usuário
Create User senac
Identified by senac;
Grant create session
to senac;
Create table senac.numeros (codigo number(6));
Insert into senac.numeros values(1); --O usuário senac não tem cota em disco, por isso não consegue fazer o insert
Fiquem a vontade para comentar e sugerir melhorias e/ou correção dos exemplos acima.
Assinar:
Postagens (Atom)